Visitorパターンを使わなくても「構造と処理の分離」ってできるのでは?
私はデザインパターンの勉強のために、結城浩さんの「Java言語で学ぶデザインパターン入門」を読んでいて、そのうちVisitorパターンのところを読んでいました。

Visitorパターンでは、データ構造と処理を分離します。そして、データ構造の中をめぐり歩く主体である「訪問者」を表すクラスを用意し、そのクラスに処理をまかせます。
とあり、Visitorパターンの主な目的はデータ構造と処理との分離であると言及されています。この点に関してはWikipedia等他のウェブサイトを見ても大体一緒だと思います:
Visitor パターン - Wikipedia
この章では、ファイルシステムを模したクラスたちFileとDirectoryを走査して列挙するという目的のプログラムが書かれており、若干簡略化すると次のようなプログラムが紹介されています
visitor_test/visitor at main · ashiato45/visitor_test · GitHub:
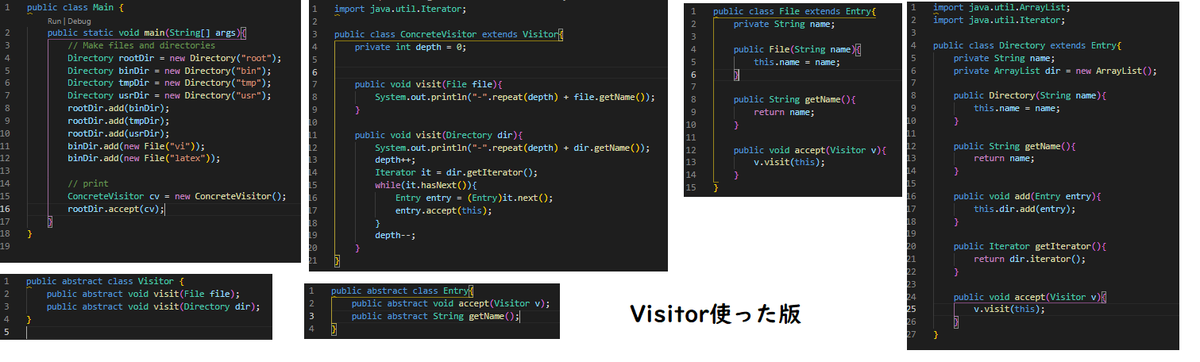
これで確かに構造(FileとDirectory)とそれらに対する処理(ConcreteVisitor)は分離されているのですが、他方OCamlのようなADTのある言語でどう書くかということを想像すると、パターンマッチと再帰関数で次のように書かれることが多い気がします:
これをJavaで模して書くとinstanceofを使うことになり、次のようになります
visitor_test/functional at main · ashiato45/visitor_test · GitHub:

これでも構造(FileとDirectory)とそれらに対する処理(walk)が分離できているように見えます。こちらのほうが余計な(?)クラスが減って、より素直に目的が達せられているように見えるので、Visitorパターンはなぜ使われるのだろうというのがよく分からなくなりました。そこで、Twitterでみなさんに聞いてみることにしました:
[おしえてください] デザインパターンの勉強中で、Visitorパターンを勉強しているのですが、右のようなコードでもVisitorの利点でよく言われる「構造と処理の分離」はできているような気がします。左のコードの右に対する利点はなんでしょうか。 #Java #駆け出しエンジニアと繋がりたい pic.twitter.com/s9QHPatxeg
— 足跡45(マストドンにいるかも) (@ashiato45) 2021年3月17日
いただいたコメントを参考にして書きなおしてみた
すると、以下のようなコメントをいただきました(他にもいただいていますが後で紹介します)
多分どちらも構造と処理の分離はできてるんですがVisitorの方が処理の抽象度が高い(処理が関数かクラスか)という点で有利なのだと思います。例えばVisitorの方だとVisitorインスタンスに何らかのパラメーターを設定してから使ったり別の構造に再利用したりが自然にできると思います
— 水鳥 (@mizuooon) 2021年3月17日
と思ったんですが instanceof が基本的に行儀悪いので確かにそれを避けてダブルディスパッチ的な事したいだけな気もしてきましたね
— 水鳥 (@mizuooon) 2021年3月17日
instanceof で場合分けだと、
— autotaker (@autotaker1984) 2021年3月17日
1.クラスが増えた時にメソッドが肥大化する
2.テストする時に特定のクラスだけ挙動り差し替えたいに不便
そのため結局クラスごとにメソッドに切り出すことになります。そうした時に、1つのクラスにメソッドをまとめるより各クラスに分散させる方がJavaらしいです。
確かに1つのEntryのサブクラス(今の場合はFileとDirectory)に対する処理はテストの観点やメソッドのサイズの問題から1つのメソッドになっていた方がいいなと思い、しかしながら「別にVisitorを使ったダブルディスパッチの形にすることなくない?」と思って私は次のようなコードを書いてみました
visitor_test/walker at main · ashiato45/visitor_test · GitHub:

これは、先程のwalkをWalkerというクラスに包み、そのなかでFileとDirectoryを引数としてオーバーロードでwalkを定義するものです。
なるほど、やっぱりVisitor(ダブルディスパッチというべきかも)は必要だわ
が、先程のプログラムはコンパイルが通りません。問題は以下の16行目で、
Directoryの中身はEntry型ということしか分からず、Entry型そのものに対するwalkは定義されていないのでコンパイルが通りません*1。
ご指摘いただきいましたが、オーバーロードの呼出はコンパイル時に解決できる必要があります:
メソッドのオーバーロードはコンパイル時に決定されなきゃいけないのでダメなやつでふね。
— autotaker (@autotaker1984) 2021年3月18日
シンボリックリンクを【意識】(つまり、例えばフラグ次第でディレクトリへのリンクは再帰walk()したりしなかったりする)したwalk()を【追加】(置き換えではなく)するにはどの部分が変更されるか、とか考えてみたらいいんじゃ
— NODA Kai (@nodakai) 2021年3月18日
コンパイル通らないのはwalk(Entry e)がないんだから当たり前ですよね
そういうわけで、walkをオーバーロードで定義する以上はどのwalkが呼び出されるかをちゃんと指定する必要があり、そのためにはvisitされる各クラスにちゃんとacceptを用意して「visitor.accept(this)」することになり、自ずとVisitorパターンが導かれるということが分かりました。
まとめ
「構造と処理の分離」というだけならVisitorパターンはいらなそうですが、その分離をした上でさらにメソッド分割やオーバーロードといったオブジェクト指向的に好ましいスタイルで記述するためにはVisitorパターンを使う必要があるようです。
コメントをいただいて教えてくださったみなさま本当にありがとうございました。
その他にいただいたコメント
他にも教えてくださった方が沢山いらっしゃったのでご紹介します:
使ってない版だと walk の中の分岐がダサいし、将来的に巡回する要素のタイプが増えたときにバグり易そうな気はします。
— 🦅あえとす⛩️ (@aetos382) 2021年3月17日
Entryの実装クラスが100個くらいある場合を考えると利点がはっきりしてくると思います。典型的なユースケースはコンパイラの構文木に対する処理の実装で、どんなEntryに何をしてどんな結果を蓄積するのか、構文木の側では意識せずにVisitorの実装に集約でき、別のVisitorの追加も簡単です。
— 異国カラス (@outlandkarasu) 2021年3月17日
コレじゃ駄目ですか?(…と関数型に持って行こうとするコードを全力で非効率なオブジェクト指向に引き戻してぶち壊しにする^^;)→https://t.co/cb3oMoOlzN https://t.co/ZVid6rmzI6
— sumim (@sumim) 2021年3月18日
*1:一応この継承関係だと、どのwalkが呼び出されるかに曖昧性はなく実行時型情報で解決されるものと思っていました…