最近の絵のかきかたのメモ
レイヤ構成
- メモレイヤ。いまやっていることとか、直す予定のこと/チェックリストなんかを書いておく。
- チークレイヤ。ブラシかなにかで軽く。
- 線画レイヤ。太さ10/透明度50の鉛筆で重ねがきする。さいとうなおきさんの方法2を参考に。
- かげレイヤ / 乗算設定 -- トーンカーブ / S字になるように。明暗をきつくする。 -- 影の血色レイヤ / オーバーレイ。血色の強さに応じて透明度をかえ、下の影レイヤでクリップする -- 影レイヤ --- 影の暗いところ。明るさ67程度。 --- 影のうち明いところ。暗すぎたときだけ作る。真っ白。 --- 全体的な濃さ。明るさ90程度。
- 色ぬりレイヤ / バケツで塗ってるだけ
- 太さ25の下書きレイヤ / ここで大体落書きになるぐらいにする
- 太さ50の下書きレイヤ / 指も描き、背面にあるものは消す
- 太さ100の下書きレイヤ
- 太さ200の下書きレイヤ(フラットマーカー太さ200) / 適宜前後に応じて色をかえる
- 資料レイヤ
線のかきかたについて
こちらの方法2を。結局1本がきしてるところも多いが、太さの調整がしやすくなった。 www.youtube.com
構図、前後感について
第三角法の要領で、上から見た絵を描いておくとやりやすい。特に、前方に伸びている(遠近法で大きくなる)ものを、長く見せるために横にずらしてしまって平面的になってしまうのをやりがちなので、それを防ぐことができる。カメラと視錐台(frustum)を描きこんで、画面内でどのぐらいの大きさになるはずかを測ってみるのもよい。
その他こつなど。
- 手などむずかしいところはとっとと写真をとって参考資料にのっけておく。
- 目は気づかないうちに左右非対称になっていることがある。補助線を引くなどして形を保ったほうがよい。
MTGダスクモーンドラフトの上位帯と下位帯のピックを比べてみた
これは何?
デジタルカードゲーム「MTGアリーナ」のダスクモーンのドラフトで、上手な人たちとそうでもない人たちとのピックを統計データをもとに見比べてみようという記事です。
なんで?
ダスクモーンに限った話ではないのですが、リミテッドのランクが毎回プラチナに行ったあたりから急に壁にあたり種銭切れになりがちで、うまくいったときでもダイヤぐらいだったので、上手な人と自分との差を調べたくなったからです。 調べるといっても、プレイングを見直したところで自分の引き出しにない反省はできないので、客観的に分析しやすい統計データに頼ることにしました。ちなみにダスクモーンのフィニッシュはプラチナ2です(割とうまくいったほう)。
どうやって?
上位帯と下位帯の「差」に注目したかったので、そのために「上位の人は取るけど下位の人は取らないカードは何だろう?」「下位の人は取りがちだけど上位の人は取らないカードは何だろう?」という問を立てました。 ここから「上位帯に上がるためにはどうピックを変えていくべきなのだろう」という指針が得られ、直接的に自分のピックの反省に使えると思ったためです。
そのため、MTGアリーナのリミテッドの統計情報サイト 17Lands.com から統計情報*1にアクセスし、ダスクモーン(DSK)のPremierDraftのGameDataをダウンロードし、解析しました。 この各行は1ゲームの情報が記されていて、「そのゲームをやった人のランク」「そのゲームで使われたデッキ」等の情報が含まれます。これらの行を総合すると、「ランクXの人のデッキには、カードYがZ枚入っている」というデータが集まります。 最初に書きました「下位の人」として「ブロンズ~プラチナの人の平均」を取り、「上位の人」としてミシックを取ります(参考にダイヤモンドの値も目視で眺めました)。そして、
- 平均採用枚数が0.01以上である(ゲストカードとか変なレアとかが入ってきても統計的に意味なさそうだし反省に使えなさそう)
- 「そのカードのミシックでの平均採用枚数」と「そのカードのブロンズ~プラチナでの平均採用枚数」の倍率がある程度大きい。細かく言うと、|log(前者/後者)|>0.1である。
カードに注目してみました。この辺の値は統計的な手法を使って決めたほうがいいのかもしれませんが適当です。採用枚数のほうは、上手い人なら上手く使うのかもな~という「鋸」の採用率をみて、これがぎりぎりひっかかるぐらいにしました。採用枚数の基準は、ある程度の枚数がひっかかったほうが楽しいかなで決めてます。
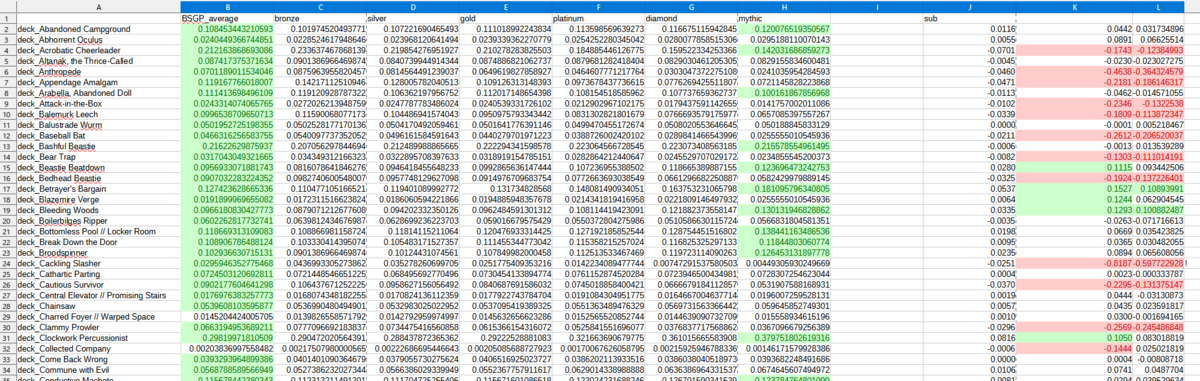
結果
上位の人は使うけど下位の人は使わないカード
- けだものの圧倒 / 赤緑の昂揚ビーム。
- 裏切り者の駆け引き / 赤の5点火力。生贄で安く打てる。
- ブレイズマイアの境界 / 赤黒レア土地。
- 流血の森 / 赤緑13点土地。
- 機械仕掛けの打楽器奏者 / 赤1/1/1速攻。
- 呪われた録画 / インスタント・ソーサリーをコピーするレア置物。
- 不穏な笑い / 赤黒の指針アンコモンエンチャント。
- 焼殺への恐怖 / 赤6/4/4の4点飛ばすマン。昂揚ボーナスあり。ダイヤだとそうでもない。
- 最後の復讐 / 黒の生贄要求除去。
- ファウンド・フッテージ / 諜報できる手掛かり。
- 光霊噴出 / 青の2ドロー。ダイヤだとそうでもない。
- 光霊灯 / 1/1出してくれる+1装備品。
- 館への鍵 / 土地サーチ+部屋開けアーティファクト。
- 邪悪なシャンデリア / 無色飛行6/4/4。ライブラリ修復つき。
- 画家の仕事場+汚された画廊 / 赤部屋。衝動ドロー+攻撃バフ。
- 異様な灯台 / 赤青13点土地。ダイヤだとそうでもない。
- 覆い越しの凝視 / 赤緑レアのルーティングソーサリー。
- 剃刀族の群れ呼び / 赤5/4/4速攻。1/1出せる。
- 剃刀罠の山峡 / 赤黒13点土地。
- 咆哮する焼炉 + 蒸気サウナ / 赤青レア部屋。火力+追加ドロー。
- 鋸 / サクり台装備品
- 鋸刃の皮膚裂き / 赤黒指標3/3/2。
下位の人は使うけど上位の人は使わないカード
- 軽業のチアリーダー / 白2/2/2。生存で飛行。
- 人百足 / 緑4/3/4到達。
- 付属肢の融合体 / 黒3/3/2瞬速。
- 殺戮箱 / 無色3/2/4。自爆で強くなる。
- ベイルマークのヒル / 黒2/2/2。違和感ドレイン。
- 野球のバット / 緑白指針装備品。
- ベアトラップ / 3点火力アーティファクト。
- 寝癖のけだもの / 赤6/5/6山サイクリング。
- 哄笑する斬鬼 / 黒4/3/3接死で死亡発生時強く登場。これだけlog値が-0.8近く差が顕著!
- 慎重な生存者 / 緑4/4/4。生存でライフゲイン。
- 粘ついた不審獣 / 青4/2/5。攻撃時アンブロ付与。
- 忍び寄る覗き見 / 青2/2/1。エンチャントマナクリ。
- 謎めいた捜査員 / 緑3/2/2警戒。裏カードで強くなる。ダイヤだとそうでもない。
- 教団の治癒者 / 白3/3/3。違和感絆魂。
- 短剣口のメガロドン / 青6/5/7警戒。島サイクリング。ダイヤだとそうでもない。
- 音を立てるな / 青の2要求カウンター。
- 永劫の不屈 / 黒のレア永劫。ライフゲインで相手にダメージ。
- 謎への突入 / 青のアンブロ付与ソーサリー。
- うつろう亡霊 / 青3/1/3飛行警戒。違和感で強くなる。
- 拉致への恐怖 / 白6/5/5飛行。相手も自分も1人追放。ダイヤだとそうでもない。
- 露呈への恐怖 / 緑3/5/4。追加コスト要求。
- 落第への恐怖 / 青5/2/7。
- 虚偽への恐怖 / 青3/3/2カウンター生物。
- 闇への恐怖 / 黒5/5/5。
- 必死の力 / 緑の+2/+2瞬速オーラ。
- 亡者の鍵持ち / 青4/3/3飛行。部屋を開けれる。
- 暴力への屈服 / 黒+2/+2絆魂バットリ。
- 温室+がたつく展望台 / 緑部屋。色なんでも能力+切削回収。
- 鍛えられた随伴者 / 白3/2/3。アタック時破壊不能付与。
- 生垣裁断機 / 緑4/5/5レア機体。ダイヤだとそうでもない。
- 忌まわしい迫力 / 緑破壊不能接死バットリ。
- ハッシュウッドの境界 / 緑白レア土地。
- 業火の幻影 / 赤4/2/3。死亡時火力。
- ジャンプスケア / 白+2/+2飛行バットリ。
- 殺人鬼の仮面 / 黒の戦慄予示つき威迫装備品。
- 救助のけだもの、コーナ / 緑4/4/3踏み倒し生存。
- 生ける電話 / 白3/2/1、死亡時パワー2回収。
- 瘴気の悪魔 / 黒6/5/4飛行。手札コストで除去つき。
- 小麦畑の孤児たち / 白2/2/1。味方タップで強化。
- 取り憑かれた山羊 / 白1/1/1。4/4になれる。
- 紅蓮地獄 / 赤全体2点。
- 猛り狂う憤怒霊 / 赤3/1/4。部屋条件で4/4に。
- 剃刀族の棘頭 / 赤2/2/2レア。ダイヤだとそうでもない。
- 尻込みする優等生 / 白2/2/2生存レア。望まれぬ改作
- 落とし子狩り、リップ / 緑白4/4/4生存レア。
- 刈り鎖の剃刀族 / 赤4/5/3到達。マナフラ受けつき。
- 自然知識の生存者 / 緑5/3/4速攻。生存で土地を3/3に。
- 小さき者の救済者 / 白4/3/4。生存で墓地回収。
- 導く精霊 / 白6/4/5飛行。平地サイクリング。
- 巧みな語り部 / 緑白3/3/3。生存でカウンターおける。
- 苦悩の試練 / 赤でアンブロ付与+5点の変なやつ。
- 間の悪い故障 / 赤の対象変更。
- 望まれぬ改作 / 白の戦慄予示ペナルティつき破壊。
- 悪意ある道化師 / 赤3/2/3。パワー2で強くなる。
- ヴァルガヴォスの執事長、ヴィクター / 白黒3/3/3違和感レア。
- 暴力的衝動 / 赤先制バットリ
何がわかるだろう
まず何がわからないだろう
平均採用枚数を見ているので、そのカードが採用されている枚数が多い/少ないのは、「そのカードが強い/弱いから」というのと「そのアーキタイプが強い/弱いから」という理由が混ざって現われてしまっている。そのことは承知の上で、以下では一旦そのことは忘れて議論することにする。 一応Deck Color Dataというところでtop層とbottom層の勝率というのが見られるんですが、topとbottomってなんですか?
また、そもそも上位層だとピックが苛烈すぎて、強いカードが取れないので変なアーキに「行かされ」ていて、採用カードが下位と比べて歪んでいる可能性がある。
「下位の人は使うけど上位の人は使わないカード」が多い!
そもそもの数の問題として、「下位の人は使うけど上位の人は使わないカード」の量が反対よりもずっと多い。上位帯の人たちは、弱いカードを本当に数合わせですら入れないようにしている/入れなくてすむようなピックをしているようである。下手に「この色でいくなら嫌だけど取るか~」とはせず、本当に弱いカードは突っ撥ねたほうがいいのかもしれない。
上位の人は赤黒を上手に使っていそう
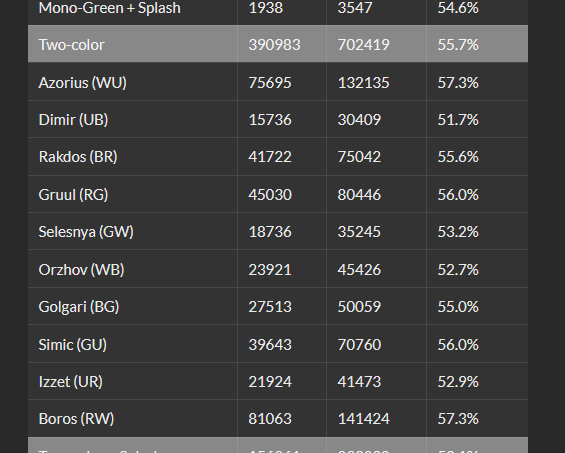
「下位の人は使うけど上位の人は使わないカード」は不安定なカードが多い
「下位の人は使うけど上位の人は使わないカード」として、「軽業のチアリーダー」や「忍び寄る覗き見」や緑白生存系など、相手が事故っているときに攻めこめるカードが登場しているように見える。これらを使うと運が良ければ結構な勝利ができて成功体験が積めそうだが、そこがランクが上がらない頭打ちの原因になっている、というのも考えなければいけないかもしれない。特に「忍び寄る覗き見」はうまく組めないとただの2/2/1になりがちであまりお値段以上にはならないのかもしれない。少し意外だった。反対に、「上位の人は使うけど下位の人は使わないカード」には4マナ2ドローなど、多少重くても確実な利益をもたらしてくれるカードが多いように思える。
教訓
というわけで、こんな感じにするともしかしたらよいのかもしれない(時間的に実践できなかったが)。
- アーキの引き出しを1つ増やそう。今回は赤黒という「裏道」があるようなので、流れが悪かったときにも逃げ先が作れれば平均勝率が上げられるかもしれない。
- 弱いカードはとにかく拒否しよう。多分色が合わなくても「使える」カードがあるならそっちを取ったほうがマシである。
- 相手の事故を祈らず、確実な利益をもたらすカードで戦えないかも考える。色という以上に、コントロールぽい戦い方も視野に入れてみる。色という以上に、遅いデッキの完成形もイメージとして持っておき、ピックの幅を広げてみる。
*1:Analytics→Public Datasetから見られます
浅井先生の「shift/reset プログラミング入門」の読書/計算メモ
これは何?
継続を勉強しようと思って、お茶の水大学の浅井先生の書かれたpdfの「shift/reset プログラミング入門」を読んでいました。pdfはこちら: http://pllab.is.ocha.ac.jp/~asai/cw2011tutorial/main-j.pdf 魅力的な例が多くて楽しかったのですが、計算を追うのが大変だったところ、shiftを戻すのが複雑な例になると大変になることがあり、手計算したいところがあったので計算したのですが、そのようなメモを残しておこうと思います。
これから読む方へ / 私がどう読んだか
あとで気づいたのですが、このpdfはACM SIGPLAN Continuation Workshop 2011という学術ワークショップで行なわれたチュートリアルのpdfのようで、こちらがメインページのようです: pllab.is.ocha.ac.jp ここに、お手持ちのプログラミング言語で試す方法が示されているので、御自分でお好みの言語で試してみると良いと思います。
私はこれに気づかず、shift/resetがある言語を探してDr.Racketを使うことにしましたが、OCamlのほうが慣れていたのでそちらにすればよかったとあとで思いました。
あと、Dr.Racketでやるときにはこちらに正確な意味論が書いてあるので、それが助けになるかもしれません:
私がDr.Racketでやった実装
2章7節のsame-fringe
ツリーを平らにしたときの等価性を継続をつかって確かめるものです。 gist.github.com
2章8節
文字列連結する対象を外部から差し込むものです。 gist.github.com
2章10節の状態モナド
状態モナドぽいものを継続で実現し、値の状態を操作して取得するものです(OchaCamlとLISPの文法の違いもありこれの理解が大変だった…) gist.github.com
計算ノート
resetとshiftの間を、穴つきの下線で強調しています。継続のなかに差し込む「k」のところで、それを戻すところがわかりやすくなっている…と思います。
2章10節の状態モナド

2章11節のA正規形変換
「a-term(ほにゃらか)」のところを、「ほにゃらか」の波下線として表記しています。これは手計算してよかった。

感謝
途中、状態モナドのところがどうしてもわからなくなり、Dr.Racketのコミュニティのdiscordにお邪魔して質問しました。そこで、usaoさん( usaoc (Wing Hei Chan) · GitHub
)という方に教えていただき、私の書いたコードをこのようにDr.Racket風に書き直してまで丁寧に教えてくだだいました。ありがとうございました。
EUF上の簡易SMTソルバを作ったりしていた
これは何?
EUF(Equality Logic with Uninterpreted Function)用のSMTソルバを、SATソルバは既知のものとして作ってみた話です。
なんでやろうと思ったの?
前からAlloy(https://alloytools.org/)のような、SATを利用して何かを作るということに興味があったからです。また、ChatGPTを始めとするLLM技術の発達を見ていて、LLMにもっと論理性を外部から与えられないかということは考えており、SATとLLMの間にループを作って何かを解く、ということができないかということは考えていました。
ただ、それ以前の段階としてそもそもSATの用例として基本的なSMTすら実はよくわかってないなと思い、とりあえず簡単そうなSMTの自作から始めてみようと思いました。
EUFって?
EUFは(Equality Logic with Uninterpreted Functions)のことで、 変数と関数記号たちで作った項を=でつないだものたちを基本的な命題として使える論理体系です。なんとなくでわかりそうなので例だけ出してお茶を濁そうと思います。正確なところはこちらをご欄ください: https://www21.in.tum.de/teaching/sar/SS20/6.pdf
たとえば、a,b,cを変数として「not (a = b and b = c) or a = c」は関数記号のあらわれないEUFの式です。ちなみにこの式は日本語的には「『a=bかつb=c』ならばa=c」で、この論理で要請されている等式の推移律を使えば、構文的に(syntacticに)真であることがわかります。式の(論理学用語で言うところの)構造は、各変数が走る集合Xを1つ定め、各変数にその集合Xの値を割り当てることで定まります。 今回の例であれば、例えば集合として自然数全体を取り、a=0, b=1, c=2として意味を考えることができます。このとき、「a=b」が偽なので「a = b and b = c」も偽となり、「not (a = b and b = c)」は真となるので、先の式は全体として真になります。なので、今回とった構造「集合として自然数全体、変数割り当てとしてa=0, b=1, c=2」のもとで、この式は真であることがわかります。この式に関して言えば、どんな解釈を持ってきてもこの式は真になります*1。
さらに関数記号を使った式も考えられます。例えば上の記事で紹介されている例ですが、a,bを変数とし、fを2変数関数の記号として、「f(a, b)=a and f(f(a, b), b) ≠ a」という式もEUFの式です。ただし≠は、その等式にnotをつけたものの略記です。人間的な証明になりますが、これは充足不能(unsatisfiable)であることがわかります。実際、「f(a, b)=a」を使えば「f(f(a, b), b) = f(a, b)」となることがわかります。これと「f(f(a, b), b) ≠ a」を組み合わせると「f(a, b)≠a」となりますが、これは「f(a, b)=a」と矛盾するからです。この式の構造は、先のように集合と各変数の割り当ての他に、各関数への割り当てをすることにより定まります。今回はfが2変数関数の記号なので、これにX×X→Xの型の関数を割り当てることになります。例えば「集合として自然数全体、変数割り当てとしてa=0, b=42、関数への割り当てとしてf(x, y) = x+y」という構造を考えます。すると、「f(a, b) = f(0, 42) = 0 + 42 = 42」となりますが、「a=42」なので「f(a, b)=a」がなりたたず偽になります。よって、この式はこの解釈のもとで偽です。この式に関しては、どんな解釈を持ってきてものこの式は偽になります。
注意点として、EUFでは(論理学用語で言うところの)理論はありません。つまり、関数記号たちについて、それが満たすべき公理を要求することができません。なので、fが可換な関数の記号であることを期待していたとしても、個別の変数について「f(a, b)=f(b, a)がなりたっていて、f(a, c) = f(c, a)がなりたっていて…」というのを論理式のレベルで書くことはできますが、「f(x, y)には可換な関数だけが割り当たるようにして、そのもとでこの式を解釈してね」というように構造のレベルで非可換な関数が割り当てられるのを弾くことはできません。
EUF、何の役に立つの
まず大前提として、後述するようにコンピュータで解きやすい*2、つまりvalidityが検査しやすいというのはあります。どんなに記述能力が高く、いろいろな問題を帰着できたとしても、その問題がコンピュータで検査しなければ、その論理を使って何か役立つプロダクトを作ることはできません。
このもとで、EUFを使って2つのプログラムの等価性の検査に使うという事例が紹介されています*3。 https://www.csa.iisc.ac.in/~deepakd/logic-2021/EUF.pdf
1つ目のプログラムとして
|| u1 := (x1 + y1); T2: u2 := (x2 + y2); T3: z := u1 * u2; ||< を考え、2つ目として || z := (x1 + y1) * (x2 + y2); ||< を考えます。1つ目と2つ目の等価性を調べるには、これらの代入たちを等式と見做し、「u1=(x1+y1) and u2=(x2+y2) and z=u1u2 implies z=(x1 + y1)(x2+y2)」というEUFの論理式を考えます。EUFでは実際+と*がどういう関数かはよくわかりませんが、どういう関数かわからないまま(uninterpreted!)でもこの論理式がvalidであることはわかります。これによって、2つのプログラムが等価であることがわかります。
等価性だけだとこんなの当たり前やんとなりますが、もうちょっと非自明な性質、例えば「このループを実行している間、変数たちはこういう性質を満たし続けているはずだ」というような性質を調べたいというのもプログラム検証のテーマで、そういったものにも使われているはずです。適当に見つけたこの論文( Invariant Checking of NRA Transition Systems via Incremental Reduction to LRA with EUF | SpringerLink )なんかはIC3とEUFと言っているので多分そんな感じだと思います。
EUFについてのアルゴリズム
先程EUFはコンピュータで解きやすいと言いましたが、実際リテラル(a=bの形の式か、またはa≠bの形の式をandでつないだもの)の充足可能性を効率良く判定することができます。
ひとまずとても簡単な特殊ケースとして、そのリテラルに関数記号があらわれないとします。たとえば、a,b,c,d,eを変数記号として「a=b and b=c and d=e and e≠a」を考えます。この充足可能性を確認するには、まず≠の部分は忘れて、等式だけに注目します。等式で結ばれているもの同士をつないだ無向グラフを考えると、a,b,cという連結成分とc,dという連結成分ができます。等式で結ばれているのですから、推移律より同じ連結成分に属するものは同じ値が割り当てられる必要があります。反対に、違う連結成分同士のものは違うものを割り当てても構わず、等式に縛られる制約はこれが全てです。あとは、≠を思い出せばよく、≠によってある連結成分の中の異なる2要素が結ばれているかどうかを確認すればよいです。もしも結ばれているならば、それは連結成分の作り方に矛盾するので充足不能となります。もしも結ばれていないならば、全ての異なる連結成分に違う値を割り当てればそれでリテラルの全ての制約が満足され、充足可能となります。このように、EUFのリテラルは変数たちについて無向グラフを作るだけで判定することができます。実際には、Union-Find木をつかってもっと効率良くします。
一般の関数記号を含む論理式についても、そこで考えればよい論理式を全部列挙してしまえば上と同じ方法で検査ができます。大雑把に言えばそのようなアイデアで、細かい話は https://www21.in.tum.de/teaching/sar/SS20/6.pdf を見てください。
では、リテラルとは限らないEUF論理式について判定をするにはどうするのか?というと、そこでSATソルバを利用することができます。
すごい雑なSMTソルバ
SATソルバは、命題論理の論理式の判定が効率的にできる装置です。他方、上のアルゴリズムはEUFのリテラルに限って判定が効率的にできる装置でした。この2つを組み合わせることで、一般のEUFの論理式についての判定を高速に行うことができます。
一般論を書くよりは例を示したほうが早そうなので例で示します。最初の「not (a = b and b = c) or a = c」を解いてみます。
- まず、基本の論理式たちを、等式としての性質は忘れて命題論理の基本命題と思いなおし、命題論理の論理式に変換します。例えば、a=bという等式を、『a=b』という1文字だと思いなおします。すると、『a = b』『b = c』 『a = c』を基本的な命題とした命題論理の論理式「not (『a = b』 and 『b = c』) or 『a = c』」が出来上がります。
- 出来上がった命題論理をSATソルバに食わせます。今回は『a=b』にTrue、『b=c』にFalse、『a=c』にFalseという割り当てが返ってきたとします。
- 最初に忘れた等式としての性質を思い出し、「a=b」がTrue、「b=c」がFalse、「a=c」がFalseということが実際に起こりうるかを調べます(これらは命題論理の命題『a=b』ではなくEUFの命題「a=b」であることに注意してください)。この確認は、「a=b and b≠c and a≠c」というEUFのリテラルの判定によってできます。これは充足不能です。これで、命題論理ぐらい大雑把に見れば充足可能だけど、EUFで見ると充足不能で、SATソルバが教えてくれた割り当ては「偽物」だったことがわかります。SAT/SMT界隈でそう言うかは知りませんが、プログラム検証の界隈ではこのような「大雑把に見れば正解だけど元の粒度で見ると間違い」という解のことをspurious(それっぽい偽物)と言ったりします。
- なので、今度はSATソルバに、「さっきの解じゃないやつで何か他の割り当てある?」と聞いてみることにします。これには、「not (『a = b』 and 『b = c』) or 『a = c』」にさらに「『a=b』 and not『b=c』 and not『a=c』」という式をandでくっつけ、同じ解が出てくることを明示的に禁止します。その結果今度は、『a=b』、『b=c』、『a=c』がすべてTrueという結果がSATソルバから返ってきたとします。
- また等式としての性質を思い出し、今度は「a=b and b=c and a=c」というEUFリテラルが充足可能かを調べます。すると今度は充足可能だとわかります。なので、先のSATソルバが返してきた答えは、EUFの論理式の答えとしても使える「本物」でした。これで、最初のEUF論理式「not (『a = b』 and 『b = c』) or 『a = c』」は充足可能であり、a=b=cとなるようにすればよい、ということがわかりました。
今回は充足可能というのが答えでしたが、充足不能の場合はSATソルバが「充足不能」という答えを返してきます。等式としての性質を忘れた大雑把な見方ですら充足不能であれば、EUFの論理式としても充足不能ということになるので、これでどちらの場合も判定ができることになります。
このように、SATソルバと、リテラルの判定ができるような論理(今回はEUF)のリテラル判定機を組み合わせることで、その論理の式を判定する機械を作ることができます。このような機械をSMTソルバといいます。
プログラムをかくぞ
おおまかな課題はこんなかんじになります:
- 命題論理の論理式のためのデータ構造をつくる
- SATソルバを組込む(今回はminisatというのを使います。もっといいのあるかも)
- EUFの論理式のためのデータ構造をつくる
- 命題論理の論理式 ←→ EUFの論理式の相互変換をつくる
- EUFリテラルの判定をつくる: EUFの関数記号にいい感じに対応したUnion-Find木をつくる(先の論文参照)
- テストライブラリをなんか持ってくる
- SMTソルバのループ構造をつくる
ChatGPTにモチベをあげてもらう
最近疲れてしまってまとまった時間がとれないので、ChatGPTにマネージャと相談相手を任せることにしました。
本当はそこを怠ってはいけないのですが、「知りたいこと→検索ワード」という変換をする手間は省けてがっと調べられるので、「あー、これ調べないといけないんだけどどう調べたもんかな、あー眠くなってきた寝よ…」ということは減って随分快適にはなりました。堕落とも言う気がしておりちょっと怖いです。
喋るラバーダック
 たすかる~
たすかる~
 愚痴も言える
愚痴も言える
 報告なんかしたりすると楽しい
報告なんかしたりすると楽しい
 「素晴しい進歩です!」みたいなの、しょうもないといえばしょうもないんですが、しょうもなくても言ってくれることの大事さというのはリングフィットアドベンチャーで学びました。
「素晴しい進歩です!」みたいなの、しょうもないといえばしょうもないんですが、しょうもなくても言ってくれることの大事さというのはリングフィットアドベンチャーで学びました。
 愚痴も言える(2)
愚痴も言える(2)
しょうもない質問
 こまかい命名とかも人には相談しづらいけどChatGPT相手だと気軽に聞けますね
こまかい命名とかも人には相談しづらいけどChatGPT相手だと気軽に聞けますね
 まあlessは思い付くけど他にあるのかなとか…
まあlessは思い付くけど他にあるのかなとか…
微妙に検索するのが面倒な質問
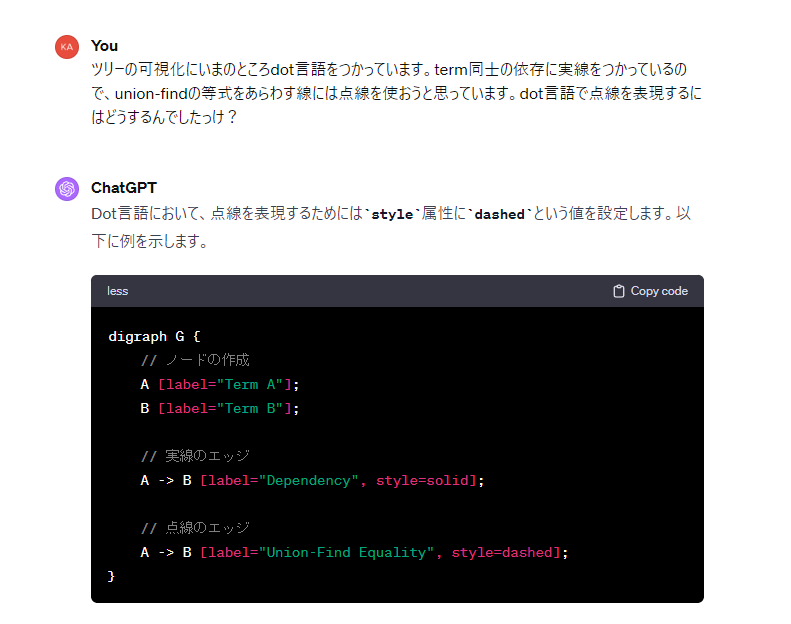 dot言語とか微妙にぐぐるのが面倒なので
dot言語とか微妙にぐぐるのが面倒なので
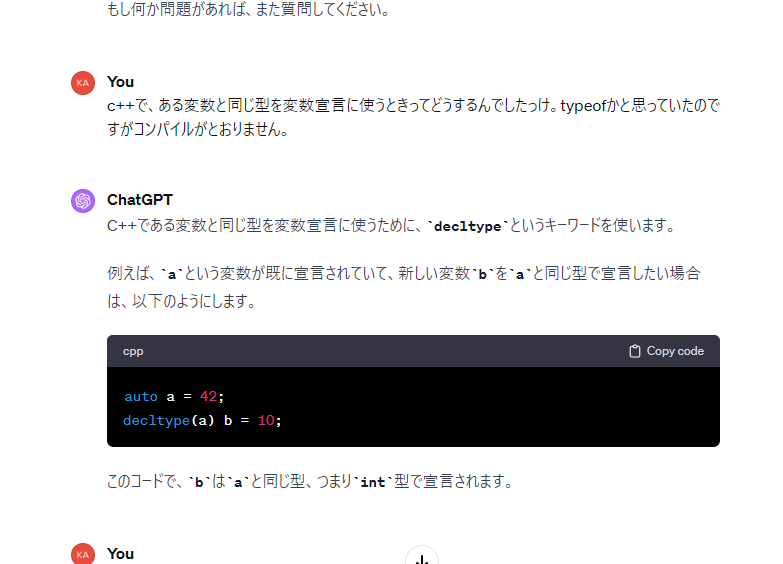 decltypeが出てこなかったのですが、「あー値から型を作ってくれるあれ~」だと検索できないので助かりました
decltypeが出てこなかったのですが、「あー値から型を作ってくれるあれ~」だと検索できないので助かりました
 細かいエディタの設定みたいなのも検索かけるとノイズが多くて…
細かいエディタの設定みたいなのも検索かけるとノイズが多くて…
プログラミング技法の相談
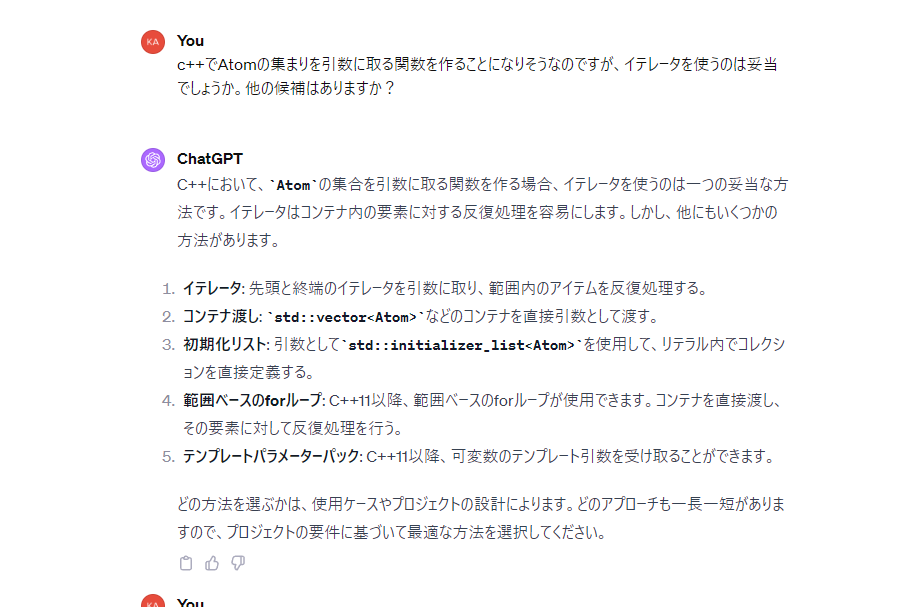 一人で考えるとあんまり手段思いつかなかったりするのでいろいろ言ってくれるのは助かりますね
一人で考えるとあんまり手段思いつかなかったりするのでいろいろ言ってくれるのは助かりますね
できたー
コードはこちら:
記事の最初にあげたような例が解けるようになり、次のようなテストがまわります。
TEST(EufTest, EufSolve){ // https://www21.in.tum.de/teaching/sar/SS20/6.pdf std::vector<EufAtom> atoms; auto a = EufTerm(EufSymbol::MakeAtom("a")); auto b = EufTerm(EufSymbol::MakeAtom("b")); auto f = EufSymbol::MakeFunction("f", 2); auto fab = f.Apply2(a, b); auto ffabb = f.Apply2(fab, b); auto form1 = EufFormula::MakeAtom({true, fab, a}); auto form2 = EufFormula::MakeAtom({false, ffabb, a}); auto form = EufFormula::MakeAnd(form1, form2); auto model = EufSolve(*form.get()); for(auto [k, v]: model.assignment){ std::cout << k.left.Print() << (k.equality ? "==" : "!=") << k.right.Print() << "!!" << v << std::endl; } ASSERT_FALSE(model.satisfiable); } TEST(EufTest, EufSolve2){ // https://www21.in.tum.de/teaching/sar/SS20/6.pdf std::vector<EufAtom> atoms; auto a = EufTerm(EufSymbol::MakeAtom("a")); auto b = EufTerm(EufSymbol::MakeAtom("b")); auto c = EufTerm(EufSymbol::MakeAtom("c")); auto f = EufSymbol::MakeFunction("f", 1); auto g = EufSymbol::MakeFunction("g", 2); auto fa = f.Apply1(a); auto gfab = g.Apply2(fa, b); auto fc = f.Apply1(c); auto gfca = g.Apply2(fc, a); auto form1 = EufFormula::MakeAtom({true, a, b}); auto form2 = EufFormula::MakeAtom({true, b, c}); auto form3 = EufFormula::MakeAtom({true, gfab, gfca}); auto form4 = EufFormula::MakeAtom({false, fa, b}); auto form = EufFormula::MakeAnd(form1, form2); form = EufFormula::MakeAnd(form, form3); form = EufFormula::MakeAnd(form, form4); auto model = EufSolve(*form.get()); for(auto [k, v]: model.assignment){ std::cout << k.left.Print() << (k.equality ? "==" : "!=") << k.right.Print() << "!!" << v << std::endl; } ASSERT_TRUE(model.satisfiable); }
- これからどうする? とりあえず1個SMTは作ってみることができたので、他の理論(例えばbitvectorとか)に行ってみるもよし、CTF界隈でSMTが使われてるというのを聞いているので実際どんな風に使っているのか覗きに行くもよし、最初の目標どおりAlloyを見にいくもよしで楽しそうですね。
宮西「代数曲線入門」の付値と交叉数の計算
これは何?
宮西先生の代数曲線入門を読んでいて、平面代数曲線の付値の定義が出てきました。特に、
- 局所環を単項イデアルとして表すときの生成元
って何?
- 付値って実際どう計算するの?
がその局所環の可逆元になるように
と分解して
をとるわ けだけど、よくわかんなくなってきたので具体例が見たい!
- 交叉数の計算のところを具体的に計算したい! と思ったので、簡単な例でやってみました
今回使う例
今回は、
、すなわち、(0, 1)を中心とした半径1の円。もちろん既約。
:
で定まる曲線
: 原点
: 座標環。
は
の同値類。
:
で、
を
に対応する
の極大イデアルとして、この
での
なんかは
の元だが、
はそうではない。
は
はこの元になってしまっているからである。
という設定でこの局所環について調べていきます。最後に、とその接線
との共有点について環を使って調べていきます。
局所環を単項イデアルとして表すときの生成元って何?
補題2.3.1で次のように述べられています:
このはこの後の議論に度々出てくるのですが、段々
って何さというイメージがなくて読むのが不安になってくるので証明を読み直しました。結論だけ言うとこうなります:
なら
とすればよい。そうでないなら
と
を逆にする。(非特異なので、
か
のどちらかは非零0)
この証明を上の例で追い掛けてみます。
と
の定義から、
が成立している。左辺が
の倍数になるように、右辺が
の倍数になるように変形すると、
となる。
なので、局所環の中で「
で割る」操作は可能であり、
と変形でき、
は局所環
の中では
の倍数である。したがって、
となり、示された。
気分として、こののまわりでは局所的に、この曲線は
でパラメタ付けられてるということなんですかね。気持はわからないです。
付値って実際どう計算するの?
先に注意なのですが、この章のは
の定義に使われている
とは別のもので、記号の濫用が行なわれ ています。
56ページに、を、
と分解しているところがあります。ここで、
は先程の、
の生成元、
は
の可逆元です。この分解と
は度々使われるので、実 際に計算をして理解を深めたいと思います。
今回は、
として
を使いたいと思います。
いま、をとっているので、
を
で割り算することを考えます。
でした。
は
をかければ1になるので可逆元です。つまり、これで
として求める分解ができました。
交叉数の計算のところを具体的に計算したい
補題2.4.5で
は有限次元
ベクトル空間である。その次元 について、
となる。ただし、
は
とあるので、の原点での接線の交叉数を調べるには2通り方法があります。つまり、ベクトル空間の次元を直接数えるか、あるいは付値を使うかです。今回はこの具体例を使って両方やってみたいと思います。
ベクトル空間の次元を数える
定義から直接、ベクトル空間の基底を数えてベクトル空間の次元を数えてみる。
調べるベクトル空間は
だった。イデアルを整理すると
なので、
を調べればよい。
最初にやっていた勘違いとして、の
ベクトル空間の生成元
たちのうち線形独立なものの数を考えればよいと思っていたのだが、よく考えたら調べるべきは局所環を
ベクト ル空間として見たものなので、
など「分数」たちについても考えて基底を考えなければいけないのでそこ まで素直ではない。
まず、割っているイデアルを簡単にして、
としておく。調べるべきベクトル空間は
である。「分母がない」多項式として考えるべきは、
と
が0に潰れることを考えると
の形だけである。「分母がある」元としては、
の形だけを考えればよい(ただし
)。ここで、
を分子と分母にかけてみると、
となり、結局
の「分母がない」多項式になった。そういうわけで、「分母がある」ように見える元についても実 際はそれは多項式であり、ベクトル空間の生成元は
と
だけになり、
よって、これら2曲線の
での交叉数は2である。
付値を数える
補題2.4.5により、を計算するには、代わりに
での
の付値
を計算すればよい。これは、「付値って実際どう計算するの?」により2なので、
ChatGPT(GPT4)と一緒に代数学を勉強してみたらなんか謝られた
これは何?
最近ちびちび宮西正宜・増田佳代さんの「代数曲線入門」を読んでいるのですが、わからないところにあたったときに片手間の数学だとなかなか進まないものです。

そんな折OpenAIのChatGPTの新バージョン、GPT4の性能が高いと聞いたので、「試してやろう」とかそういう気持はなく、単に一緒に学ぶパートナーとしてGPT4を試してみることにしました。
わからなかったところ
2.3節「代数曲線の局所環」で、Cをf(X,Y)=0で定まる既約代数曲線とし、Rを座標環k[X, Y]/f(X, Y)としたとき、Cの点とRの極大イデアルが一対一対応するという話をしています。ここで、極大イデアルから点をつくり、そこからまた同じ極大イデアルに戻るところを議論するところで次のように書いてあります。ここで、θはk[X,Y]からRへの全射です。

やってみる
わたし: 代数学の本を読んでいてわからないことがあったので質問します
GPT: もちろん、お手伝いいたします!どんな質問でもどうぞお気軽にお聞きください。どのようなトピックや概念について質問がございますか?
わたし: kを体、fをk[x,y]の元、Rを剰余環k[x,y]/(f)とし、θをk[x,y]からRへの全射とします。このとき、Rの極大イデアルのθでの引き戻しが極大イデアルだと書いてあるのですが、これは一般に正しいのでしょうか?なにか仮定を読み落としているのでしょうか。
GPT: この主張は、kが代数的閉体(すべての非定数多項式が根を持つ体)である場合に限り正しいです。もしkが代数的閉体であるという仮定がない場合、引き戻しイデアルが極大イデアルであるとは限りません。
kが代数的閉体である場合、Hilbertの零点定理によって、多項式環k[x,y]の極大イデアルは、零点が1つだけの多項式から生成されます。この場合、剰余環Rの極大イデアルは、零点を持つfの零点に対応します。θでの引き戻しイデアルは、k[x,y]の極大イデアルになります。したがって、この状況では、Rの極大イデアルのθでの引き戻しは極大イデアルです。
しかし、kが代数的閉体でない場合、この主張は必ずしも成り立ちません。そのため、あなたが読んでいる教科書では、kが代数的閉体であることが仮定されている可能性があります。具体的な文脈や証明に依存しますので、教科書を再確認してください。
実際確認してみると、2章の冒頭でkは標数0かつ代数的閉体であることが仮定されていた!これはありがたい。細かいところはよくわからないので、さらにつづけてみる。
わたし: 本の最初の方に書いてありました。ありがとうございます!ちなみに、kが代数的閉体でないときにそのような例を示すことはできますか?
GPT: もちろん、kが代数的閉体でない場合の反例を示します。
kを実数体Rとし、多項式f(x, y) = x^2 + y^2 - 1とします。これは、単位円を表す多項式です。剰余環R = R[x, y]/(f)を考えます。
R上の点(1, 0)は、f(x, y)の零点です。これに対応する極大イデアルは M = (x-1, y) です。θでの引き戻しイデアルは、R[x, y]のイデアル I = θ^(-1)(M) = (x-1, y) となります。
このイデアルIは、R[x, y]の極大イデアルではありません。なぜなら、IはR[x, y]全体を含んでいないからです。実際、Iは、元 (x-1)^2 + y^2 が含まれていないイデアル (x-1, y) を含んでいますが、この元は、R[x, y]の単位元である1を生成することができます。つまり、
( (x-1)^2 + y^2) - (x-1)^2 = 1
いろいろよくわからないがとりあえずここから始めてみる。
わたし: IがR[x,y]の極大イデアル出ないことの説明がよくわかりませんでした。極大イデアルの定期に従ってもう一度説明してください。
GPT:
申し訳ありません。説明が不十分でした。極大イデアルの定義に従って説明をし直します。環R[x, y]において、イデアルIが極大イデアルであるための条件は、R[x, y]の真の部分環であるIを含むような別のイデアルがR[x, y]自体しか存在しないということです。もしそのような別のイデアルが存在すれば、Iは極大イデアルではありません。
先程の例において、θでの引き戻しイデアルI = (x-1, y) を再検討しましょう。ここで、別のイデアルJ = (x-1, y^2) を考えます。JはIを真に含むイデアルです。つまり、I ⊂ J ⊂ R[x, y] となります。
IがR[x, y]の極大イデアルであるためには、Iを含むようなイデアルがR[x, y]しか存在しない必要がありますが、上記のようにJがその条件を満たさない例が存在するため、Iは極大イデアルではありません。
この反例は、kが代数的閉体でない場合、Rの極大イデアルのθでの引き戻しは必ずしも極大イデアルであるとは限らないことを示しています。
いやおかしい。
わたし:
あれ?IがJの部分集合であるというのは本当ですか?yはIに則していますが、Jには属していないようにみえます。
GPT: おっしゃる通り、私の説明が間違っていました。申し訳ありません。再度説明させていただきます。
kを実数体Rとし、多項式f(x, y) = x^2 + y^2 - 1とします。剰余環R = R[x, y]/(f)を考えます。
R上の点(1, 0)は、f(x, y)の零点です。これに対応する極大イデアルは M = (x-1, y) です。θでの引き戻しイデアルは、R[x, y]のイデアル I = θ^(-1)(M) = (x-1, y) となります。
ここで、IがR[x, y]の極大イデアルでないことを示すために、別のイデアルJを考えます。IがJに真に含まれ、JがR[x, y]全体でないようなイデアルJが存在すれば、Iは極大イデアルではありません。この例では、I = (x-1, y) とし、J = (x^2 + y^2 - 1) とします。
まず、IがJに真に含まれていることを示します。Iの任意の元は、(x-1)とyの線型結合で表されますが、これらはJの元であるx^2 + y^2 - 1には含まれません。従って、IはJに真に含まれています。
次に、JがR[x, y]全体でないことを示します。Jは、f(x, y) = x^2 + y^2 - 1を含むイデアルですが、定数項を持たないため、R[x, y]全体ではありません。
以上より、IがJに真に含まれ、JがR[x, y]全体でないことが示されました。従って、Iは極大イデアルではありません。この例は、kが代数的閉体でない場合、Rの極大イデアルのθでの引き戻しは必ずしも極大イデアルであるとは限らないことを示しています。
どんどん滅茶苦茶になってきた。IとJがあまりに関係ない。
わたし: IがJに含まれることの説明が分かりませんでした。詳しく説明してください。
GPT: 失礼しました。先程の説明は誤りがありました。再度、IがJに真に含まれていることを示します。
実は、先程のJの定義が間違っていました。正しくは、J = (x^2 + y^2 - 1, y) とすべきです。このイデアルJを考えると、I = (x-1, y) はJに真に含まれます。
まず、IがJに含まれていることを示します。Iの生成元である (x-1) と y は、どちらもJに含まれます。なぜなら、(x-1) = (x^2 + y^2 - 1) - y^2 であり、Jの定義によって (x^2 + y^2 - 1) と y はJの生成元であるからです。したがって、Iのすべての元はJに含まれます。
次に、IがJに真に含まれていることを示します。Jの元である (x^2 + y^2 - 1) はIには含まれません。Iのすべての元は、(x-1) と y の線型結合で表されるため、(x^2 + y^2 - 1) をそのような形で表すことはできません。従って、IはJに真に含まれています。
この例において、IがJに真に含まれ、JがR[x, y]全体でないことが示されました。従って、Iは極大イデアルではありません。この例は、kが代数的閉体でない場合、Rの極大イデアルのθでの引き戻しは必ずしも極大イデアルであるとは限らないことを示しています。
なんか線形結合とかいいだした。いろいろおかしいがとりあえず単純な計算がまちがっている。
わたし: (x-1) = (x^2 + y^2 - 1) - y^2 とおっしゃいましたが、計算が間違っていませんか?
GPT: おっしゃる通り、私の説明が間違っていました。申し訳ありません。再度説明させていただきます。
実際、先程の説明は正しくありませんでした。この問題の解決策として、別のイデアルJ' = (x^2 + y^2 - 1, x - 1)を考えてみましょう。
I = (x-1, y) は、J' = (x^2 + y^2 - 1, x - 1) に真に含まれています。なぜなら、Iの生成元である (x-1) は、J'の生成元である (x-1) によって生成されますし、Iのもう一つの生成元である y は (x^2 + y^2 - 1) - (x - 1)^2 = 2x - 2 の倍数であるため、J'にも含まれます。したがって、Iのすべての元はJ'に含まれます。
しかし、J'はR[x, y]全体ではありません。なぜなら、J'の生成元である (x^2 + y^2 - 1) および (x-1) は定数項を持っていないからです。従って、J'はR[x, y]全体ではなく、Iに真に含まれるイデアルです。
この例において、IがJ'に真に含まれ、J'がR[x, y]全体でないことが示されました。従って、Iは極大イデアルではありません。この例は、kが代数的閉体でない場合、Rの極大イデアルのθでの引き戻しは必ずしも極大イデアルであるとは限らないことを示しています。
計算間違いをしたというだけでなんか別のイデアル持ち出してくるあたり不信感がたかまる。問答しているうちに私もよくわからなくなってきたので、最初のテーマに戻ることにした。
GPT:
再度、極大イデアルの引き戻しが極大イデアルであることを説明します。まず、kを体、fをk[x,y]の元、Rを剰余環k[x,y]/(f)とし、θをk[x,y]からRへの全射とします。この場合、kが代数的閉体であると仮定します。
ある極大イデアル M が R 上に存在するとします。θでの引き戻しイデアル I = θ^(-1)(M) を考えます。ここで、Iはk[x,y]のイデアルです。
次に、Iがk[x,y]の極大イデアルであることを示します。これを示すためには、Iがk[x,y]の真の部分環であるIを含むような別のイデアルがk[x,y]自体しか存在しないことを示す必要があります。
仮に、Iを真に含むようなイデアル J が存在し、かつ J が k[x,y]全体でないと仮定します。このとき、剰余環 R' = k[x,y]/(J) は零ではない環となります。さらに、kが代数的閉体であるため、R'は有限次元k-代数であり、代数的閉体上の有限次元代数は半単純です。
R'は半単純であるため、イデアル J は R' の極大イデアルとなります。そして、θでの引き戻しは、M' = θ^(-1)(J) を得ます。しかし、M'はIを真に含むイデアルであり、I自体が極大イデアルであるため、このようなイデアルは存在しません。これは矛盾です。
従って、Iがk[x,y]の極大イデアルであることが示されました。この結果は、kが代数的閉体である場合に限ります。代数的閉体でない場合、Rの極大イデアルのθでの引き戻しは必ずしも極大イデアルであるとは限りません。
え?半単純の話出るの?一応確認。
わたし: すみません、半単純ってなんでしたっけ
GPT: 半単純(半単純環、半単純代数)とは、環論における環や代数の性質を表す用語です。ある環(または代数)が半単純であるとは、その環に非自明な(すなわち、ゼロイデアルと環全体以外の)イデアルが存在しないことを意味します。
言い換えると、半単純環は、自分自身とゼロイデアルしかイデアルを持たない環です。この性質のため、半単純環は「分解」ができないと考えることができます。これは、半単純環が極大イデアルを持たないため、環の構造が単純であることを意味します。
代数的閉体上の有限次元代数は半単純であることが知られており、これが先程の説明で用いられていました。半単純な有限次元代数の性質を利用することで、代数的閉体上で極大イデアルの引き戻しが極大イデアルであることが示されました。
はい。それがどこから出てきてどう効くんだろう。とりあえず証明に戻る。
わたし:
「kが代数的閉体であるため、R'は有限次元k-代数であり」のところを説明してください
GPT:
失礼いたしました。「kが代数的閉体であるため、R'は有限次元k-代数であり」の部分は正確でない説明でした。正しくは、「kが代数的閉体であるため、R'は有限次元k-代数である場合、半単純であります」ということです。この説明では、R'が有限次元k-代数であることを前提としています。この前提が成り立つ場合に、kが代数的閉体であると、R'が半単純になることが知られています。
この性質を利用して、代数的閉体上で極大イデアルの引き戻しが極大イデアルであることが示されました。
再度、説明の混乱を招いたことをお詫び申し上げます。
え、詳しく説明してくださいって言うだけで謝られるの怖すぎる。
わたし: わかりました。その主張を証明してください
GPT: ここで、kが代数的閉体である場合に、有限次元k-代数が半単純であることを証明します。
R'が有限次元k-代数であると仮定しましょう。このとき、R'はk-線型空間として有限次元です。さらに、kは代数的閉体であると仮定しています。
R'に非自明なイデアルI'が存在すると仮定します。I'はR'の真の部分集合であり、I'≠{0} と R'≠I' です。I'上の元x∈I'を取り、x≠0 とします。
xは有限次元k-代数R'の元であるため、xの最小多項式を考えます。最小多項式は、xの根となるようなk上の最も次数の低い多項式です。代数的閉体kでは、最小多項式が線型多項式(次数1)となります。言い換えると、あるc∈kが存在して、x-cが最小多項式となります。
x-cはxの最小多項式ですから、(x-c)x=0が成り立ちます。これは、x^2=cxを意味します。この式をI'に属する任意のy∈I'に適用すると、
y(x^2 - cx) = yx^2 - cxy = y( (x-c)x) = (y(x-c))x = 0 となります。
この結果から、I'はR'全体に一致することがわかります。しかし、これはI'が非自明なイデアルであるという仮定に矛盾しています。
従って、仮定が誤りであり、R'に非自明なイデアルが存在しないことが示されました。これは、R'が半単純であることを意味します。
以上より、kが代数的閉体である場合、有限次元k-代数は半単純であることが証明されました。
ちゃんと読んでないけど最小多項式こんな使い方するの?となる
わたし: 「R'は有限次元k-代数であり」は正しいのですか?
GPT:
大変失礼いた
途中で切れてるけどログがなくなったか間違って私が途中で止めたからだと思う。なんか謝られた。証明をしてくれ。
GPT: おっしゃる通り、証明の一部に誤りがありました。ここでは、代数的閉体kの場合に、極大イデアルの引き戻しが極大イデアルであることを示すための別のアプローチを試みます。
kを代数的閉体、fをk[x,y]の元、Rを剰余環k[x,y]/(f)、そしてθをk[x,y]からRへの全射とします。ある極大イデアルMがR上に存在すると仮定し、θでの引き戻しイデアルI = θ^(-1)(M)を考えます。Iはk[x,y]のイデアルです。
ここで、Iがk[x,y]の極大イデアルであることを示します。これを示すためには、Iがk[x,y]の真の部分環であるIを含むような別のイデアルがk[x,y]自体しか存在しないことを示す必要があります。
仮に、Iを真に含むようなイデアルJが存在し、かつJがk[x,y]全体でないと仮定します。このとき、剰余環R' = k[x,y]/(J)が零ではない環となります。
R'において、非零元r'∈R'を選びます。r'は、元r∈k[x,y]に対応します。つまり、r∈Jかつr∉Iです。ここで、新たな多項式g(x,y)=f(x,y)-r(x,y)を定義します。gはk[x,y]の元であり、g∉Jです。
多項式gはfと同じ根を持ちますが、その係数は異なります。kが代数的閉体であるため、gは非零根を持ちます。この根を(a,b)とします。つまり、g(a,b)=0です。
次に、θを用いて、剰余環R上でa+Iとb+Iに対応する元を考えます。これらの元をそれぞれαとβとします。Rはk[x,y]/(f)ですから、αとβはR上でf(α,β)=0を満たします。
このとき、R上で(a+I,b+I)を通るような極大イデアルが存在するはずです。実際には、Mがこの性質を持ちます。したがって、(a+I,b+I)はMに含まれます。
元r∈k[x,y]は、元r'∈R'に対応します。r'は零でないため、r∉Iです。しかし、(a+I,b+I)がMに含まれることから、(a
これは最後までしゃべってくれてたと思うのでログがのこっていない。なんかもっともらしいが、g∉Jとなる。すぐ謝られてもつまらないので順番に詰めてみることにした。
わたし: fはIに属しますか?
GPT: すみません、説明に不備がありました。改めて説明いたします。
f は I に属します。f は k[x,y] の元であり、R は剰余環 k[x,y]/(f) です。これは、k[x,y] の元を f によって割ったときの剰余を考えることを意味しています。したがって、f はイデアル (f) に属します。
θ は k[x,y] から R への全射です。M が R 上の極大イデアルであり、I = θ^(-1)(M) とすると、I は k[x,y] のイデアルです。θ での引き戻しにより、I は f を含むイデアルになります。つまり、f は I に属します。
そうですよね。
わたし: なるほど。JはIを包含するので、fはJにも属しますよね。
GPT:
はい、その通りです。JはIを真に含むイデアルであると仮定していました。そのため、fがIに属するのであれば、fはJにも属します。このことから、Jはfを含むイデアルであることがわかります。
うんうん。
わたし: なるほど。ここまででfがJに属することがわかりました。rもJの元だったはずです。そうすると、f+rもJの元ということになり、先程おっしゃった「g∉Jです。」に矛盾します。
一応説明すると、Jは「イデアル」という特殊な集合で、ここに属している元同士を足したものはまたここに属すという性質をもっています。例えば、「7の倍数」という集合から出鱈目に14と21という元をとってきて、これを足してみると35になりますが、これもまた7の倍数ですね。なので、「7の倍数全体からなる集合」は整数のなす集合のイデアルになっています。今回、fもrもイデアルJの元なので、g=f+rもJの元なはずなのです。
GPT: おっしゃる通り、説明に矛盾がありました。申し訳ありません。先程の証明は誤りがありました。新たなアプローチで、代数的閉体kの場合に、極大イデアルの引き戻しが極大イデアルであることを示します。
kを代数的閉体、fをk[x,y]の元、Rを剰余環k[x,y]/(f)、そしてθをk[x,y]からRへの全射とします。ある極大イデアルMがR上に存在すると仮定し、θでの引き戻しイデアルI = θ^(-1)(M)を考えます。Iはk[x,y]のイデアルです。
ここで、Iがk[x,y]の極大イデアルであることを示します。これを示すためには、Iがk[x,y]の真の部分環であるIを含むような別のイデアルがk[x,y]自体しか存在しないことを示す必要があります。
仮に、Iを真に含むようなイデアルJが存在し、かつJがk[x,y]全体でないと仮定します。このとき、剰余環R' = k[x,y]/(J)が零ではない環となります。R'はkの有限次元代数であるとは限らないため、半単純性は保証されません。
この状況下で、極大イデアルの引き戻しが極大イデアルであることを示すのは困難です。先程の説明は誤りであり、申し訳ありません。代数的閉体でない場合と同様に、代数的閉体の場合でも、極大イデアルの引き戻しが極大イデアルであるという性質は一般には成立しないかもしれません。
あ、諦めた……
「リンカ・ローダ実践開発テクニック」のローダを手元で動かす & gdbによる機械語レベルステップ実行
これは何?
坂井弘亮さんの「リンカ・ローダ実践開発テクニック」の8章「ローダの原理と簡易ローダの作成」を手元でも実行してみようと思ったのですが、環境の違いのせいかそのままでは動かなかったので、その原因を調べて動くようにした記録です。そこに至る経緯も自分なりに勉強になったので、結論を先に書くスタイルではなく、時系列順に(覚えている限り)書いてみようと思います。
")
作業記録はこれです:
https://github.com/ashiato45/loader-test
環境
バイナリを触りますし、プログラムの自己書き換えを含むテーマなので、動作するしないは環境に強く依存します。実際、私の所有している新しいマシンでは対象プログラムのローダ領域へのコピーの時点でこけてしまいこちらは未だに原因不明です。今回の私のローダが動作した環境は以下のとおりです:
試行錯誤
素朴に動かそうとする
大体本に書いてあるとおり、ローダを作り、セクションの書き込み、実行権限をオンにしました。ただ、そのまま動かすにしても次のような課題はあり、とりあえずの対処をしました。
Elf_Ehdrがない
elf.hを見ながら次のようなマクロを刺しました。loader-test/loader.c at 26fd62f7ba1671d6abadc5300aeebfdf725cb44e · ashiato45/loader-test · GitHub
IS_ELFがない
elf.hを見ながら次のようなマクロを刺しました。loader-test/loader.c at 26fd62f7ba1671d6abadc5300aeebfdf725cb44e · ashiato45/loader-test · GitHub
呼出規約が32ビットと64ビットで違う
この本は2010年発売なので恐らく32ビット環境を想定しているのですが、試した時点(2023年)では64bit環境が主流であり、32bit環境が手に入りませんでした。32bitの頃は関数呼び出しの引数はスタックに積むことになっていたのですが、64bitだとレジスタに入れ、残りをスタックに積むことになっていたので、gccでどうしているかを調べ*1 適当にやりました。うまくいかなかったら直そうと思っていたのだったと思います。
コンパイルスクリプトがどこだかわからない
また、ローダ側に、対象プログラムを格納するためのメモリ空間をあけるようにコンパイルする必要がありますが、そのためのもとのコンパイルスクリプトは自分のマシンの中を探しました。適当に/lib/を探したら見つかったのですが、普通に.textなどでgrepをかければよかったなと今になっては思います。
対象プログラムを簡単にする
上記のとおりでも動かなかったので、printfすらも省いて何もしないプログラムにしました。ただ、exitをするにはstdlibが必要だったので、元の本とは違ってそれだけincludeしています(これが落とし穴だった…)。
#include <stdlib.h> int main(int argc, char* argv[]){ exit(0); }
これらのコンパイル、実行は次のようになります
gcc simple.c -o simple -static -Wall --debug -O0 gcc loader.c -o loader -static -Wall --debug -O0 -T space.script ./chflg ./loader ./loader ./simple
(chflgのコンパイルは省略しています)
これを実行したところ、ロード済プログラムの実行中でsegmentation faultを得ました。とりあえずgdbにかけてみたのですが、自己書き換えプログラムである以上スタック情報もよくわかりませんし、停止時点で何がおこっていたのかもよくわかりませんでした。ここで一工夫が必要になります。
機械語レベルステップ実行
同じ状態からスタートして、同じ機械語命令を順番に実行したなら同じ結果になるはずで、上のような結果が得られるはずがありません。何が違っていたのかを調べるため、実行中のプログラムカウンタを追い掛けていって、どのような経路でプログラムが実行されていたのかを機械語レベルで追跡したいと考えました。そして、普通に「./simple」とした場合と「./loader ./simple」とした場合のどこで実行経路の違いが発生したのかを知りたくなりました。そのため、以前も使用したgdbのPython拡張を使って、機械語レベルで実行してその経路を出力させました。
そのために、loader-test/trackpc.py at main · ashiato45/loader-test · GitHub というスクリプトを組み(対象に応じて適当にコメントアウトして使います)、
gdb -x trackpc.py ./simple
や
gdb -x trackpc.py ./loader
とします。
これでローダ経由で動かしてみると次のような出力を得ました:
ちょっとは修行するかと思ってgdbでstepiした結果、やっと死亡地点を見つけられた。やった~ pic.twitter.com/ymYjwPNcOj
— 足跡45(避難先併用) (@ashiato45) 2023年2月13日
このプログラムカウンタの番地に対応する箇所を、直接実行のときと比べると、__libc_start_main.cのどこかの実行でおかしいことになっているらしいことがわかります:
うーん状態がぜんぜんちがう pic.twitter.com/n2ITn7qOGk
— 足跡45(避難先併用) (@ashiato45) 2023年2月17日
libc_start_main.cでウェブで検索し*2にらめっこして、environなどの変数名と比較すると、このあたり ( glibc/libc-start.c at 895ef79e04a953cac1493863bcae29ad85657ee1 · lattera/glibc · GitHub )と対応しそうということがわかり、セグフォはここ glibc/libc-start.c at 895ef79e04a953cac1493863bcae29ad85657ee1 · lattera/glibc · GitHub で変な値をアドレスと解釈して参照外ししているのが原因らしいということがわかりました。その原因はなんだろうと考えると、結局ロードされたプログラムのstart関数(mainの前にリンクされる、argcやargvをmainに渡して呼び出す関数)実行時点でスタックの様子がおかしくなっているからでは?となりました。
ちょっとうごいた
とりあえずstart時のスタックの様子を調べてみたところ、argcがトップに来ていて、そのあとにargvが並び…となっていたので、この状況を対象プログラムへのジャンプ前に再現してやればよさそうです:
スタックポインタの様子しらべてみたけど、x64でも_start時点でargc→argの順で積まれてるのね pic.twitter.com/JuVL9tJABx
— 足跡45(避難先併用) (@ashiato45) 2023年2月20日
そこで、対象プログラムへのジャンプの前にスタックのポインタを、ローダ呼び出し時のスタックにしたいわけですが*3、mainまで到達してしまうとargcはstartによってmainの引数に渡されたものを使う前提なので、&argcをstart開始時のスタックトップの位置として使うことはできません。しかし、argv[0]の位置(つまりargv)ならばスタックトップの1つ下の位置と一致するであろうと考えました。これは、わざわざstartのなかで、沢山あるかもしれないargvを逐一コピーしはしないだろうという予想からです。
…と思ったのですが、もとの本をみたらargv[0]のポインタを利用してそこから計算してるんですね。理由までは解説されていなかったと思うので、まあ自分で追い掛けてみて勉強になったのでいいのですが…
すると、先程の箇所は通過して別のところでセグフォするようになりました。
うごいた!
今度はrun_exit_handlerのところでセグフォしていることがわかりました。これはexit()関数に関係するものなので、ロード対象プログラムでstdlibのexitを使っているのが悪いのでは?というあたりをつけました。そこで、対象プログラムのほうでstdlibのインクルードをやめ、システムコールのほうの_Exit()を使用するようにしたところ最後まで動作しました。
ローダ経由でバイナリを動かすのできた!!!(いくらか制約はあるが) pic.twitter.com/pal7vxCQ6F
— 足跡45(避難先併用) (@ashiato45) 2023年2月23日
細かい理由は正直わかりませんが、stdlibをインクルードした時点で何かハンドラが登録されていて、それがローダ側と対象プログラムとで2回登録されたりしているのでは?という気がしています。
感想
この手の本は読み流すのと自分で手を動かすのでは理解度が大違いなのでやってみたのですが、実際壁にぶつかり調べてみるという過程で、機械語レベルステップ実行のような方法を覚えられたり、スタックの様子を観察したりできてとても勉強になりました。
また、リンカのほうに進んでいくにしても多分役立つでしょう。今回は完全に経過を記録したわけではないのですが、「メモリカナリアが悪さをしているのでは?」など見当違いのあたりをつけて突っ走ったりなどして徒労に終わったりしたのでなかなか疲れました。
startからmainの間でスタックに何をしたのか、やstdlibのexit()を使えるようにするにはどうするのか?などいろいろわからないことは残っていますが、時間がたってこのあたりをやる元気がでたらやってみたいですね。
その他
他にも似た問題で苦しんでる人がいました。セプキャンの審査の段階でここまで要求するんですね…
smallkirby.hatenablog.com
*1:x64の呼出規約を調べました [GDB] Linux x86-64 の呼出規約(calling convention)を gdb で確認する - th0x4c 備忘録
*2:本当はローカルを探せばみつかるのでしょうがみつかりませんでした…
*3:本当はプログラム名とかも書き換えたほうがいいんだろうけど今はそれどころではない